The curve is bending
We've finally crossed an inflection point of model utility where the output is actually worth more than the cost for real dev work. It's starting to make sense to throw lots of money towards inference.
Some devs will likely get 5-digit AI inference budgets in 2026. There will probably be some disruption of the junior dev job market, or at least disruption of what it means to be a junior dev.
This prediction is based on the last few months of using the newest generation of models and tools and feeling the productivity gains myself.
For context, my AI inference spend for productive coding work is:
- 2023 — $100/yr, Github Copilot
- 2024 — $250/yr, ChatGPT Plus
- 2025 — $5000/yr amortized, ChatGPT Pro and a lot of Claude Code use
I'll recap my last few months and extrapolate.
Nascence
o1-pro
The first inkling — noticeable only in retrospect — was the release of OpenAI's o1 six months ago. It still wasn't quite good enough to be consistently professionally useful to me, but the trend was clear. It was also the first model to solve both my private coding eval and software design eval. Sonnet 3.6 was also a not-too-distant 2nd around this time.
3 months ago, OpenAI released o1-pro with their $200/mo ChatGPT Pro subscription. After seeing some early-adopter Twitter friends sing its praises, I shelled out the money. Now I'm in the ranks of the praise-singers.
o1-pro was the first model I've found professionally useful. That is, it's the first model that can consistently code about as well as a junior engineer for tasks that can be described and solved in a single file.
Models going all the way back to GPT-3.5 in 2022 could occasionally code like a junior engineer in specific domains, and each model since then has been an incremental improvement. But o1-pro is qualitatively different.
I can paste a 1000-line Rust file, a 300-line diff, and 100-line trace output from a failed test into o1-pro and say "find where I introduced a bug". I go get a coffee, come back, and more often than not, the bug is found. This cumulatively saves me an hour or two a week just finding dumb bugs.
It feels a little silly to be copy and pasting back and forth to ChatGPT and some first-class tooling would be nice.
AI IDE
I'd tried AI editors like Cursor a year ago, but gave them up simply because the models weren't actually net-useful for my work yet. They might have been net-useful for some developers sooner depending on the type of codebase, but for the hardcore data-structures & algorithms in a spreadsheet engine, they weren't close.
The utility of o1-pro, combined with the wave of new o1-tier models (DeepSeek R1, Claude 3.7, xAI Grok 3, Gemini 2.5 Pro) that came out right behind it made me reconsider.
I happened to see a shill post for the Zed Editor while having these nascent thoughts of AI actually being professionally useful, and decided to give it a test. The main utility is the prompt library feature which lets me quickly apply English "programs" to my code.
In my work on the Row Zero spreadsheet engine, I implement a lot of spreadsheet functions (e.g. COUNTIFS, VLOOKUP, SUM, etc). Excel defines about 500 functions, and we're slowly chipping away at that list. A lot of functions are trivial and boilerplate-filled — a perfect task for an LLM.
I made a prompt with 10 examples of functions I've already defined. Now, when a customer requests a new function, I just do a /prompt spreadsheet_func and the name of the function. The prompt tells it how to lay out the function, how to write tests, what kind of edge-cases to test for, etc. I do some minor cleanup and verification and git commit. What was a 20-minute task, down to 2.
When I write some new code and want to add a randomized test, I just cmd+a to select my whole file and type /prompt randomized_test which contains that linked blog post plus 10 examples of other randomized tests from our codebase. Claude 3.7 spits out a perfectly reasonable 100-line randomized test, saving me 15 minutes.
If the test shows a problem, I just paste the whole file and the test output to o1-pro and it finds the issue more often than not.
Zed isn't a VSCode fork like the others, so took me a while to configure it how I wanted. Configuration's done by setting values in .json files instead of with a nice UI. I had trouble with this until I used gitingest to slurp the entire contents of the Zed docs repo into a single 70K-token markdown file. Now I can access that inside Zed itself with /prompt zedhelp. No configuration UI needed, now Claude does my configuring.
Growth
Intelligent microtools
After the initial success, I felt it was the right moment to seriously invest in my personal AI setup. An early example of what I mean here is Simon Willison's llm tool which lets you call LLMs from the command line, e.g. cat countries | llm "What is the capital?".
There's a whole host of specialized programs to be created here.
You want a script that scans your git diff, asks you some questions, then writes a commit message? Easy. What about one that takes a URL and emits a list of sentences that mention some topic? No problem.
These programs are trivial to write these days with structured outputs. You can write if-statements that actually look like:
if llm("{sentence} is spanish"):
do_something()But why write all these ourselves? These programs are mostly boilerplate. I put a few hand-coded examples into a prompt and had o1-pro generate more. Now I have a whole library of LLM-powered microtools, and I can make more in seconds.
I generate throwaway tools all the time now for any tasks that are shaped like "a bunch of terminal commands with a little intelligence applied on some steps".
Claude Code
Another big inflection point was Claude Code. It's basically just Claude in a command-line agentic loop that works on your codebase with frighteningly simple tools. You ask it to refactor xyz to abc and you see it literally executing grep commands to find the instances of xyz, then string-replace commands to do the refactor, etc. Despite this bare-bones toolkit, it's shockingly useful.
As a test, I rewrote my entire website backend with Claude Code before writing this post. Not only did I rewrite it, I added a ton of features. Here's what my markdown editor looks like on the backend this second:

To get that screenshot into the article I just did a screencap and a cmd+v to paste. I had Claude write an image-uploader backend so I could trivially paste or drag-n-drop images into the editor and a link gets auto-generated and auto-inlined.
In the past, the main thing that kept me from writing was the friction of dealing with images. Either you use a hosted solution like Notion that makes this easy, or you upload your images to an S3 bucket or something and add links manually. But with Claude Code, writing a whole Notion-like interface was easy.
Claude whipped up a nice image library backend that looks like this:
It has all the images from all my posts, and is currently viewing the one I just uploaded above!
The black button says "Open in Paint". As I wrote recently, I've been disappointed in existing AI image editors and had a really simple idea of what I wanted — 1990s Microsoft Paint but with AI infill. So I put all the docs for Replicate's image model APIs into my Claude Code session and had it make the paint app I'd been wanting.
While I was at it, I made a ton of other stuff in the backend admin portal — a spaced repetition app, a tool to send one-time-use file download links to friends, an LLM chat with niche features, a site metrics / pageview dashboard, and much more!
When I want a new feature, I just tab over to Claude Code to specify it. I have my CLAUDE.md file set up so Claude asks me additional questions to tease out any ambiguities in my feature request. A few minutes later I review the diff and usually it's totally adequate.
At the peak of the frenzy, I was running 3 Claude Codes all working on separate features in parallel. I just made 3 different folders all with the same git repo and treated each as a different developer, pulling/pushing/merging in github. When doing that, you really start to feel that the bottleneck is your own decision-making.
Claude Code can be pretty expensive. Doing all the rewrite and backend work of these webapps cost a few hundred dollars. It's a lot more money than most people are accustomed to spending on AI inference, but we're past a point where it's actually worth it for a lot of stuff. I've never written frontends or CRUD apps, so it would've taken me probably 100 hours to do all of these new apps manually, but less than 10 hours with Claude Code.
Looking forward
All this is to say, there's been an inflection in the last few months. We've reached the point where AI-enhanced development is good enough to help build tools that tangibly accelerate software development and facilitate the improvement of the AI itself.
The work I do isn't too qualitatively different from the work a dev does at a lab like OpenAI or Anthropic. I'm optimizing code, reducing CPU utilization, eliminating bottlenecks, implementing ever-more-clever data structures to eke out gains here and there that add up over time.
All in, AI tools that I've made with the help of AI now save me a few hours a week — about a 10% gain. I expect the AI lab developers to get a similar improvement. A 1.1x multiple in Q1 2025 compared to a year prior.
And at the same time, the models are just getting better. A few months ago, OpenAI announced that the currently-unreleased o3-high model beat the ARC challenge. If history repeats, other labs will replicate this in the next few months.
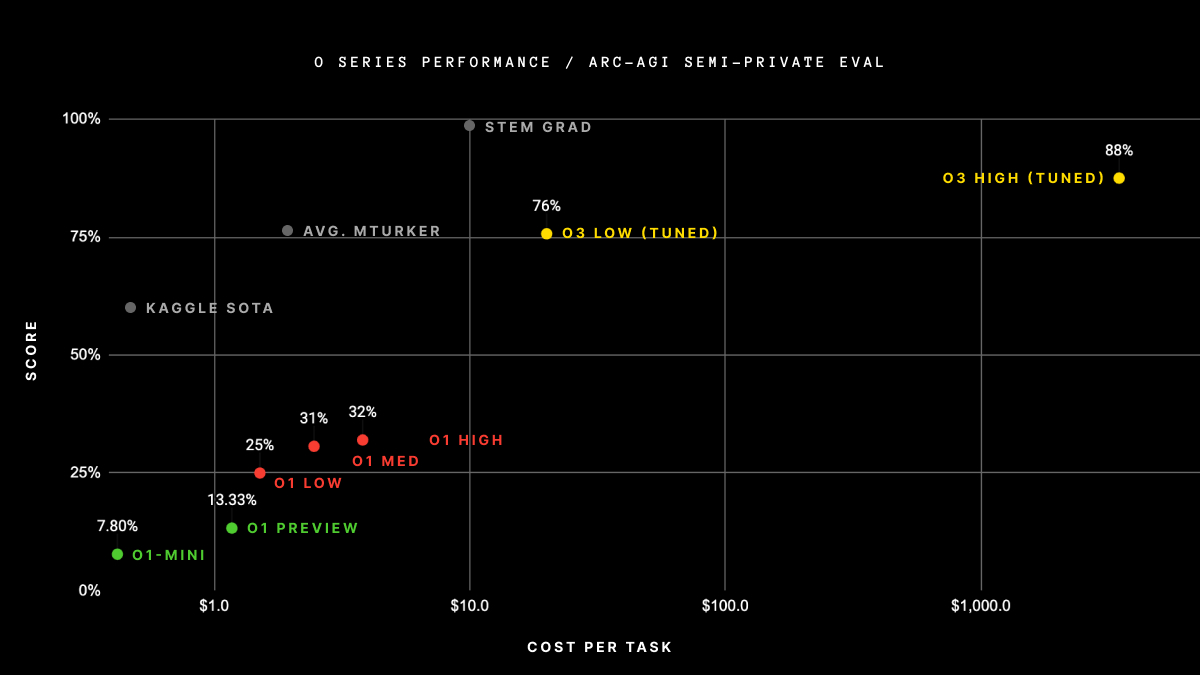
It's worth meditating on the gap between o1 and o3 on this chart. o1-pro is the first LLM I've found professionally useful, and o3 apparently dominates it in reasoning ability. It's not entirely clear how o1-pro (vs o1-high on this chart) would have performed when fine-tuned, but presumably OpenAI would have published the result much earlier if it was anywhere close to as good.
o1-pro can consistently do about as well as a decent junior dev on bounded tasks. I expect o3-pro will just be like this, but qualitatively better in most ways. And I expect the other labs aren't too far behind.
I also expect the next wave of o1-pro-and-beyond-tier models to be absurdly expensive to start. Sam Altman said they're losing money on ChatGPT Pro subscriptions. API access to o1-pro just got released at $150 per million input tokens, and $600 per million output tokens (includes the reasoning tokens). That means my "paste a thousand lines to debug" workflow would cost $10-20 if done through the API, and I do it at least once a day.
A mid-level bigtech developer is making over $100/hr, so even if it costs $100 to solve a tricky bug, that's probably a great trade. The prospect of augmenting human developers with $10-50K worth of AI use per year is no longer sounding crazy, and I'd be shocked if forward-thinking companies didn't start doing it by the end of 2025, with many more following in 2026. I assume internal use at the AI labs themselves is already getting into this territory for the power-users.
At the same time that the newest, biggest models come out with high prices, models at existing capabilities will be made smaller, faster, and cheaper. I like the whole Pareto frontier here. I want o3-pro for the hardest tasks, but also can't wait to upgrade Claude Code to o1-pro tier intelligence when inference speed and cost comes down.
Senior Dev Taste
There's also more to be gained from simply improving tooling for existing models. I'm confident I can get another 10% out of my current stack with better tooling.
An example of overhang here is what I'll call "senior dev taste". Current models have pretty bad software architecture taste. Most of the training data — random code on github, random blog posts about software development — is written without too much regard for quality. And most of the synthetic training data for writing code isn't on million-line megaprojects.
You can non-trivially improve the performance of code-writing LLMs by putting how-to-do-good-software guides written by thoughtful senior devs. In general, I get the best utility out of Claude Code when I treat it just like a junior dev out of university. I offer remarkably similar guidance and feedback to it as I have to real juniors in the past. I view my role mostly as "keeping it on the rails" and giving high-leverage nudges that will make the rest of the implementation fall into place.
Senior dev taste seems like a much harder thing to generate synthetic data and RL for. Harder to evaluate, longer feedback loops, etc. It's possible — humans do it — but harder. I mention this because I'd recently seen a debate on whether AI would replace juniors or seniors first, and I think juniors are ultimately just easier to get the synthetic data flywheel spinning on.
Without too much justification other than the pace of improvement on the models and the tooling, I expect code-writing agents to essentially match college grads in almost all software tasks by the end of 2026, but wouldn't be surprised by sooner — as early as the end of 2025 depending on the exact release cycle of the big players.
I'm not an economist and don't really know what this means for the new grad job market. These tools do raise the opportunity cost of onboarding newbies. If you make your senior engineers 2x more productive by giving them a team of AI juniors to command, that just means taking up their time to onboard a newbie is 2x more expensive, opportunity-wise.
It's also unclear to me how well human juniors can make use of these tools in a professional setting. I've seen some really impressive demos, but in my experience, it requires a lot of senior judgment to get the current generation of models to be useful on big projects, etc. The senior dev skill of quickly reviewing junior-quality code changes is also super handy.
Without making any concrete predictions, if I were a junior right now, I'd be trying to speedrun developing senior dev taste. I'll write about concrete steps on this topic soon. DMs open in the meantime.
Conclusion
AI is finally getting to the "actually net-useful" point for real software development. This is a huge non-linearity in what people are willing to pay, and we should expect spend on inference to jump from today's low-hundreds of dollars to thousands or tens of thousands. This will be an obviously good trade since it will accelerate devs by anywhere from today's 1.1x to perhaps 2-3x by the end of 2026. The curve is bending.
Appendix
A note on Jevons
When I made a tweet about this notion, a lot of people responded "inference prices have been coming down over time" and "inference is a commodity" which are obviously true but don't actually contradict the point about overall spend.
Jevons observed during the industrial revolution that increasing the efficiency of coal-burning machines led to increasing the consumption of coal. There's no reason to think AI will be any different — my own monotonically increasing annual inference spend is evidence of this.
Having GPT4 read an entire book just to look for a quote I half-remember is prohibitively expensive, so I don't do it. Having 4o do it costs a dollar, so I do. AI getting cheaper made me spend more than I would have otherwise.
Right now, a bottleneck to working on big codebases is context size. My codebase for work is on the order of a hundred million tokens. Claude Code would work a hell of a lot better if, before starting any task, it just spawned a hundred Claude Haikus to go scan the entire codebase for anything relevant and put it in context. Don't try to be smart, just scan it all!
This is currently about 100x too expensive to be reasonable. But wait a year for another 100x cost-per-unit-of-intelligence drop. I'll pay $1 per codebase scan, but it'll make the implementation go so much faster, it'll be worth it.
Cheapening models makes use go up.
Related reading
This post has been languishing in my drafts for weeks, and in that time, a lot of other senior devs have been writing similar things.
Steve Yegge wrote a piece that predicts basically the same tech arc, though reaches different conclusions about the accrual of gains.
Tweets like this by other senior devs are becoming more common:
no hype, just boringly, the wheels are really coming off with codegen finally. claude code is writing sets of 300-400 line files, and they're stable. a few models ago, it would start to tap at 120 lines, and it would be stable half the time.
— Lewis (@ctjlewis) March 16, 2025
And finally, the excellent AI 2027 scenario was just published and made me get around to actually finishing this post. Its predictions largely match up with my predictions here, though it's more about forecasting what happens after where this piece ends, a time that could get crazy and is much hazier to me than what I've laid out here. Specifically, I have doubts about the exact timelines between automating junior engineering and getting order-of-magnitude speedups of ML research.